
As we get more and more experience with LLM's I am starting to get worried that I am spending more time relying them and letting my brain atrophy rather than exercising one of my key skills - debugging problems. Like I have become dependent on things like calculators, spell checkers, grammar checkers and even something as common as the contacts list in a cell phone (I literally can't remember any number except my wife's phone number, even the number to our houses landline is a complete mystery to me).
I found myself the other day using GitHub CoPilot to write tests for a project where CI was failing because there were no tests (yes I could have written a simple
[Fact]
public void AlwaysTrueTest()
{
Assert.True(1 + 1 == 2);
} test and set the code coverage to 0% but it was an old project and I felt that there should have been tests and
this was a good time to add tests.) While Co-Pilot was great at writing some tests, when it got to testing
Controllers it couldn't really figure out return type of Async Tasks and the like.
The code it created would create an error, so I would send the error back to ChatGPT and it would try something different,
which would cause an error, which I would paste back into ChatGPT and it usually returned the first way it had done something.
I even tried switching to ChatGPT Canvas from Copilot and would
end up with the same loop of errors. This lead me to the Trough of Disillusionment,
and I realized that this has been a continuous cycle in AI over the past year two years. You see AI doing something that
is literally magic, you start using it for a while and then you realize that it is only magic in a very narrow set of circumstances.
As soon as you hit an edge case, or do something slightly more complicated then the AI frequently falls down.
Then a new model that is even more impressive comes out, and you can no longer trick it with apparently simplistic questions like which is larger 9.11 or 9.9. You start using the new model and the cycle repeats, until you start hitting the edge cases of the new model.
A project like Notebook LM comes out and the fact that it can generate seemingly
amazing podcasts like this one generated from my
"Leveraging LLMs for Coding: Insights and Real-World Experiences" post.
But after generating a few podcasts, you realize that it is a pretty neat magic trick, but you start to see the flaws in the generated podcast. The
hosts are always a little too positive, they hallucinate far too much and miss a lot for it to be that useful in actual learning,
and the same two hosts get quickly repetitive.
OpenAI introduces a new "reasoning" model that seems to be much better at writing code and solving math problems, but after a while, although it is "better" it still falls down when trying to get it to solve complex problems. For example, I wanted it to write a background image remover using EmguCV and after spending 45 minutes working with it to get it to compile -- it hallucinates a library method that doesn't exist, I paste the error into ChatGTP o-1 preview wasting one of my 30 queries of the week, rinse repeat. I finally got it to compile and run and it produced terrible results, removing half of the primary subject and leaving trees and other background objects. Code from a ten-year-old blog post Image Background Removal performed much better.
I had similar experiences with the ChatGPT Canvas feature, where for the first few days playing with it you think it will drastically change the way you work, but after a while you realize that while it is an improvement (it can actually update text and code in place, whereas in the past it replaced the entire previous effort with something new) and does better at allowing iteration - it also will duplicate code and text and if you aren't careful and look really look at the output you might not notice that it has duplicated a paragraph or a function.
A quick example, is that when writing the past couple of blog posts I have been using ChatGPT (Dall-e) to create hero images for the last couple of posts. In Same, Same, but Different I reused an old image from a previous post about Yak Shaving. I wanted to get Dall-e to create an image of Prgrammer Yak Shaving, but it seems like it is an impossibility to get Dall-e (or any of the other AI image generators) to create an image of shaving a Yak without Shaving Cream on the programmer (you can see my frustration over the conversation, as I fall into the Trough of Disillusionment).
Actual Conversation with ChatGPT

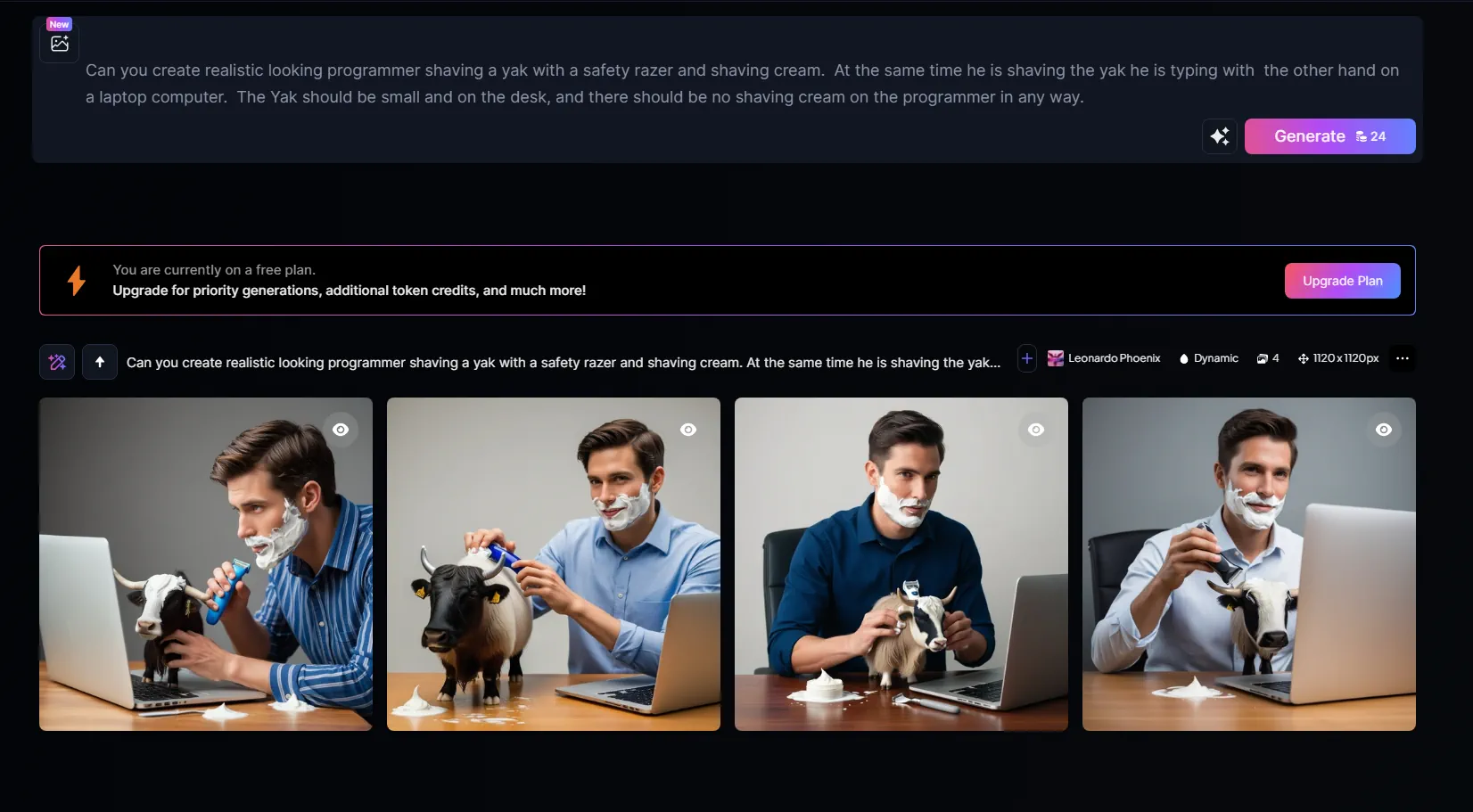
Then I tried Leonardo AI, and it was the same (it doesn't really have the same level of conversation as ChatGPT, so I didn't bother with the conversation).
Conversation with Leonard AI
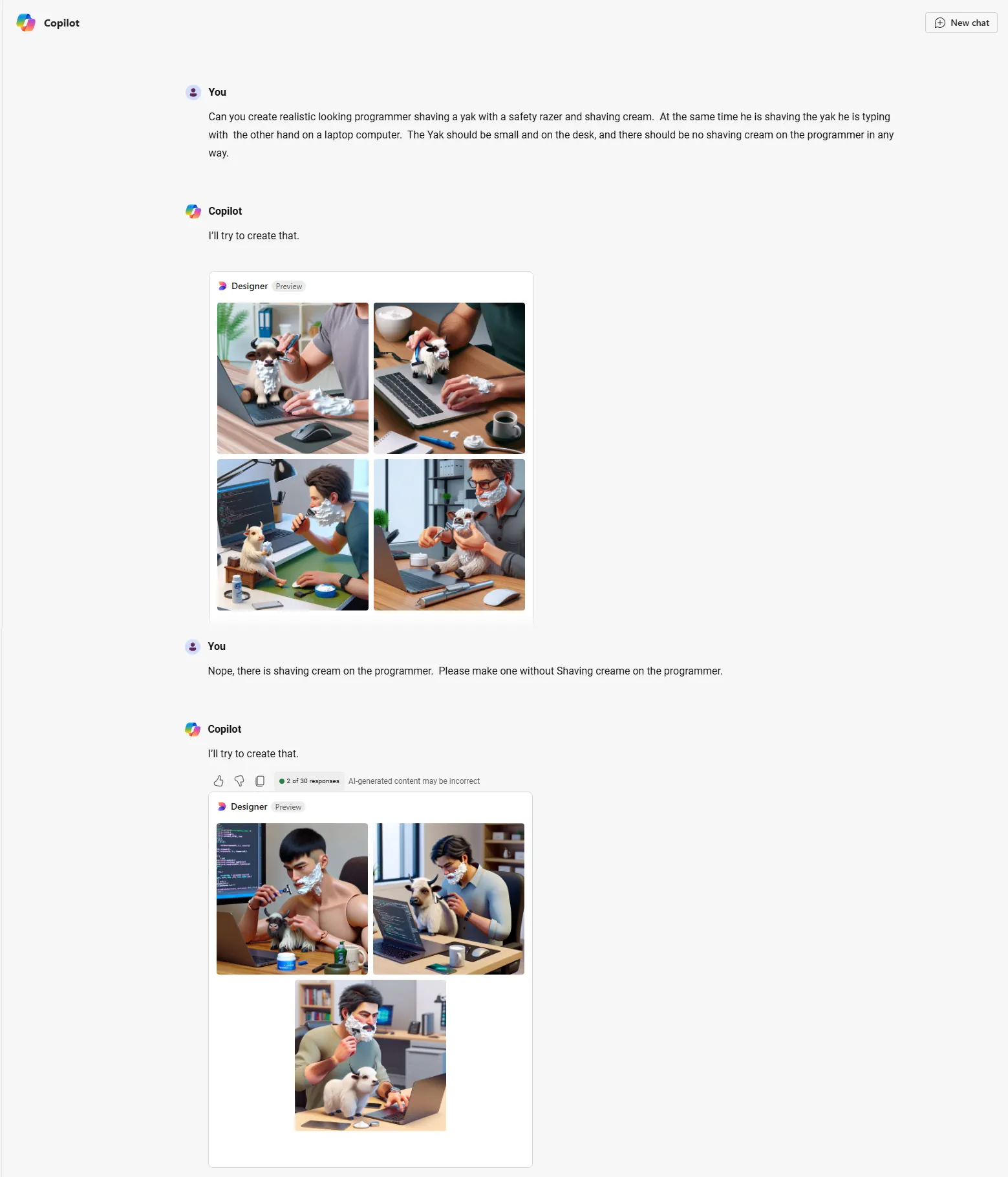
I also tried Bing Co Pilot but I is basically Dall-e with different prompting instructions and slightly different tuning.
Conversation with Bing CoPilot
I should have looked into FireFly or Midjourney but I don't have a subscription to either of those.
All this to say, is that as good as AI is sometimes, remember that is also not very good at other times. When you realize that Image generation relies upon source images that are in the training set, and there are no source images of shaving without having shaving cream on the subject. It becomes apparent that AI is not magic, it is kind of like a large lookup table. And upon hitting the edge of that lookup table, you fall into the "Trough of Disillusionment".
